Méthodes d'échantillonnage directes
Génération de nombres aléatoires selon des lois de probabilité usuelles
Il existe plusieurs manières de générer des nombres dits “aléatoires” selon des lois connues. La très grande partie des programmes informatiques ne génèrent pas des nombres totalement aléatoires. On parle plutôt de nombres pseudo-aléatoires, qui semblent aléatoires mais sont en réalité générés selon un processus déterministe (qui dépend notamment d’une “graine”).
La distribution uniforme
Pour générer un échantillon pseudo-aléatoire selon la loi uniforme sur \([0;1]\), on peut donner l’exemple de l’algorithme congruentiel linéaire (Lehmer, 1948) :
Générer une suite d’entiers \(y_n\) tel que :
\(y_{n+1} = ( ay_n + b )\text{ mod. }m\)\(x_n = \frac{y_n}{m-1}\)
Choisir \(a\), \(b\) et \(m\) de manière à ce que \(y_n\) ait une période très longue et que \((x_1,\dots , x_n)\) puisse être considéré comme \(iid\)
où \(y_0\) est appelé la “graine” (seed en anglais). On remarque que l’on a necessairement \(0 \leq y_n \leq m - 1\). En pratique on prend \(m\) très grand (par exemple \(2^{19937}\), la valeur par défaut dans R qui utilise l’algorithme Mersenne-Twister). Dans ce cours, on ne va pas plus s’intéresser à la génération de nombre pseudo-alétoires selon la loi uniforme sur \([0;1]\), il s’agit d’un outil que l’on considère fiable et qui est utilisé par les différents algorithmes présentés par la suite.
Autres distributions
Pour échantillonner selon la loi binomiale \(Bin(n,p)\), on peut utiliser les relations entre les différentes lois usuelles en partant de \(U_i\sim \mathcal{U}_{[0;1]}\): \[\begin{align*} Y_i & =\mathbb{1}_{U_i \leq p} \sim \text{Bernoulli}(p),\\ X & = \sum_{i=1}^n Y_i \sim Bin(n,p) \end{align*}\]
Pour échantillonner selon la loi normale \(N(0,1)\), on peut utiliser l’algorithme de Box-Müller:
Si \(U_1\) et \(U_2\) sont 2 variables uniformes \([0;1]\) indépendantes, alors
\[\begin{align*}
Y_1 & =\sqrt{-2\log U_1}\cos(2\pi U_2)\\
Y_2 & =\sqrt{-2\log U_1}\sin(2\pi U_2)
\end{align*}\]
sont indépendantes et suivent chacune la loi normale \(N(0,1)\).
Échantillonner selon une loi définie analytiquement
Méthode par inversion
Inverse généralisée
Pour une fonction \(F\) définie sur \(\mathbb{R}\), on définit son inverse généralisée par \[ F^{-1}(u) = \text{inf}\{x; F(x)>u\}\]
Soit \(F\) la fonction de répartition d’une distribution de probabilité, et soit \(U\) une variable aléatoire suivant une loi uniforme sur \([0;1]\). Alors \(F^{-1}(U)\) définit une variable aléatoire ayant pour fonction de répartition \(F\).
On déduit de la propriété ci-dessus que si l’on connaît la fonction de répartition de la loi selon laquelle on veut simuler, et si l’on est capable de l’inverser, alors on peut générer un échantillon suivant cette loi à partir d’un échantillon uniforme sur \([0;1]\).
On veut générer un échantillon suivant la loi exponentielle de paramètre \(\lambda\)
On a la densité de la loi exponentielle qui est \(f(x) = \lambda exp(-\lambda x)\), et la fonction de répartition (son intégrale) qui vaut \(F(x) = 1-exp(- \lambda x)\).
Posons \(F(x)=u\). On remarque alors que \(x=-\frac{1}{\lambda}\log(1-u)\).
Si \(U\sim \mathcal{U}_{[0;1]}\), alors \(X=F^{-1}(U)\sim Exp(\lambda)\).
Méthode d’acceptation-rejet
La méthode d’acceptation-rejet consiste à utiliser une loi instrumentale \(g\), dont on sait échantillonner selon la loi, afin d’échantillonner selon la loi cible \(f\). Le principe général est de choisir \(g\) proche de \(f\) et de proposer des échantillons selon \(g\), d’en accepter certains et d’en rejeter d’autres afin d’obtenir un échantillon suivant la loi de \(f\).
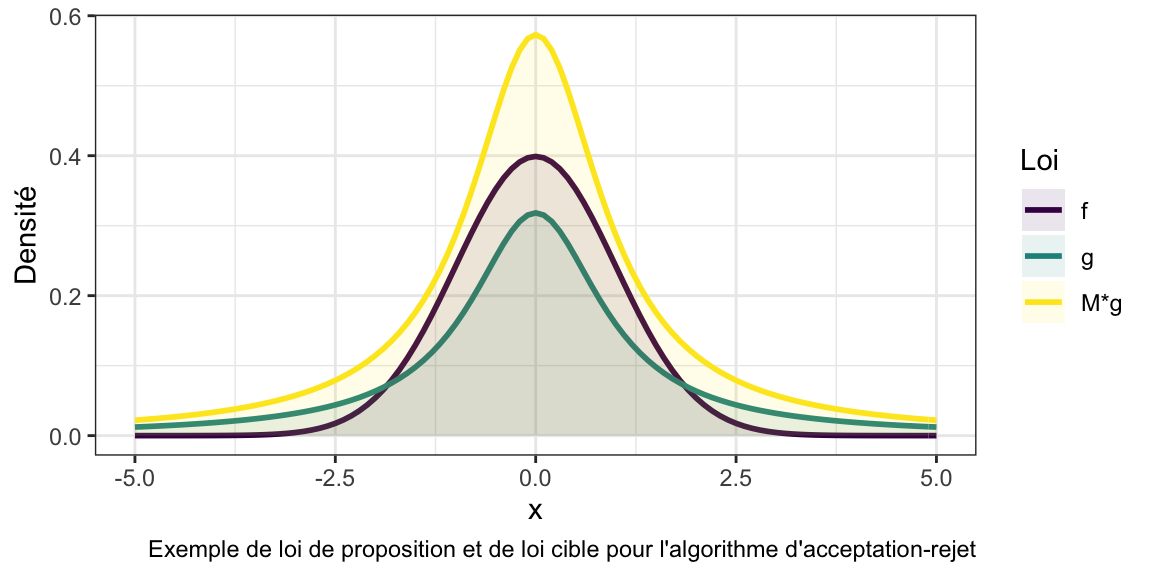
Soit une loi d’intérêt de densité \(f\).
Soit une loi de proposition de densité \(g\) (à partir de laquelle on sait échantillonner) telle que, pour tout \(x\) :
\[f(x) \leq Mg(x)\]
Pour \(i=1, \dots, n\) :
Générer \(x_i\sim g\) et \(u_i\sim \mathcal{U}_{[0;1]}\)
Si \(u_i\leq\frac{f(x_i)}{Mg(x_i)}\) on accepte le tirage:
\(y_i := x_i\)
sinon on le rejette et on retourne en 1.
\((y_1, \dots, y_n) \overset{iid}{\sim}f\)
Plus \(M\) est petit, plus le taux de rejet est faible et plus l’algorithme est efficace (au sens où il nécessite moins d’itérations pour obtenir un échantillon de taille \(n\)). On a donc intérêt à choisir \(g\) le plus proche possible de \(f\), en particulier lorsque la dimension augmente (l’impact de \(M\) étant d’autant plus important alors). Néanmoins, la loi de proposition aura nécessairement des queues plus lourdes que la loi cible, et ce dans toutes les dimensions de l’espace des paramètres. À cause du fléau de la dimension, lorsque le nombre de paramètres augmente, le taux d’acceptation décroit très rapidement.
👉 Exercice 1 : Construire un pseudo-échantillon de taille \(n\) selon la loi discrète suivante (multinomiale à \(m\) éléments \(\{x_1, \dots, x_m\}\)) : \[P(X=x) = p_1\delta_{x_1}(x) + p_2\delta_{x_2}(x) + \dots p_m\delta_{x_m}(x) \quad \text{ avec }\sum_{i=1}^m p_i = 1 \text{ et } \delta_{a}(x) = \mathbb{1}_{\{x=a\}}\]
Pour \(i = 1, \dots, n\) :
- échantillonner selon la loi uniforme : \(u_i \sim U_{[0,1]}\)
- \(y_i := x_{\min\left\{j ; u_i \in [0 ; \sum_{l=1}^j p_l]\right\}}\)
\((y_1,\dots, y_n\)) est alors un pseudo-échantillon de taille \(n\) de la loi \(Mult(p_1, \dots, p_m)\)
👉 Exercice 2 : Grâce à la méthode par inversion, générer un pseudo-échantillon de taille suivant une loi de Cauchy (dont la densité est \(\forall\, x\in \mathbb{R}\) \(f(x)=\frac{1}{\pi(1+x^2)}\)), sachant que \(\arctan'(x)=\frac{1}{(1+x^2)}\) et que \(\underset{x\rightarrow-\infty}{\lim} arctan(x) = -\frac{\pi}{2}\).
\(F(y) = \int_{-\infty}^y f(x)\text{d}x\)
Alors \(F(x) = \dfrac{\arctan(x)}{\pi +1/2}\), et il suit que \(F^{-1}(x) = \tan\left(\pi(x-1/2)\right)\).
Donc \(Y = \tan\left(\pi(U-1/2)\right) \sim \text{Cauchy}\) (avec \(U \sim U_{[0,1]}\)), et on en déduit l’algorithme suivant :
Pour \(i = 1, \dots, n\) :
- échantillonner selon la loi uniforme : \(u_i \sim U_{[0,1]}\)
- \(y_i := \tan\left(\pi(u_i-1/2)\right)\)
\((y_1,\dots, y_n\)) est alors un pseudo-échantillon de taille \(n\) de la loi de Cauchy
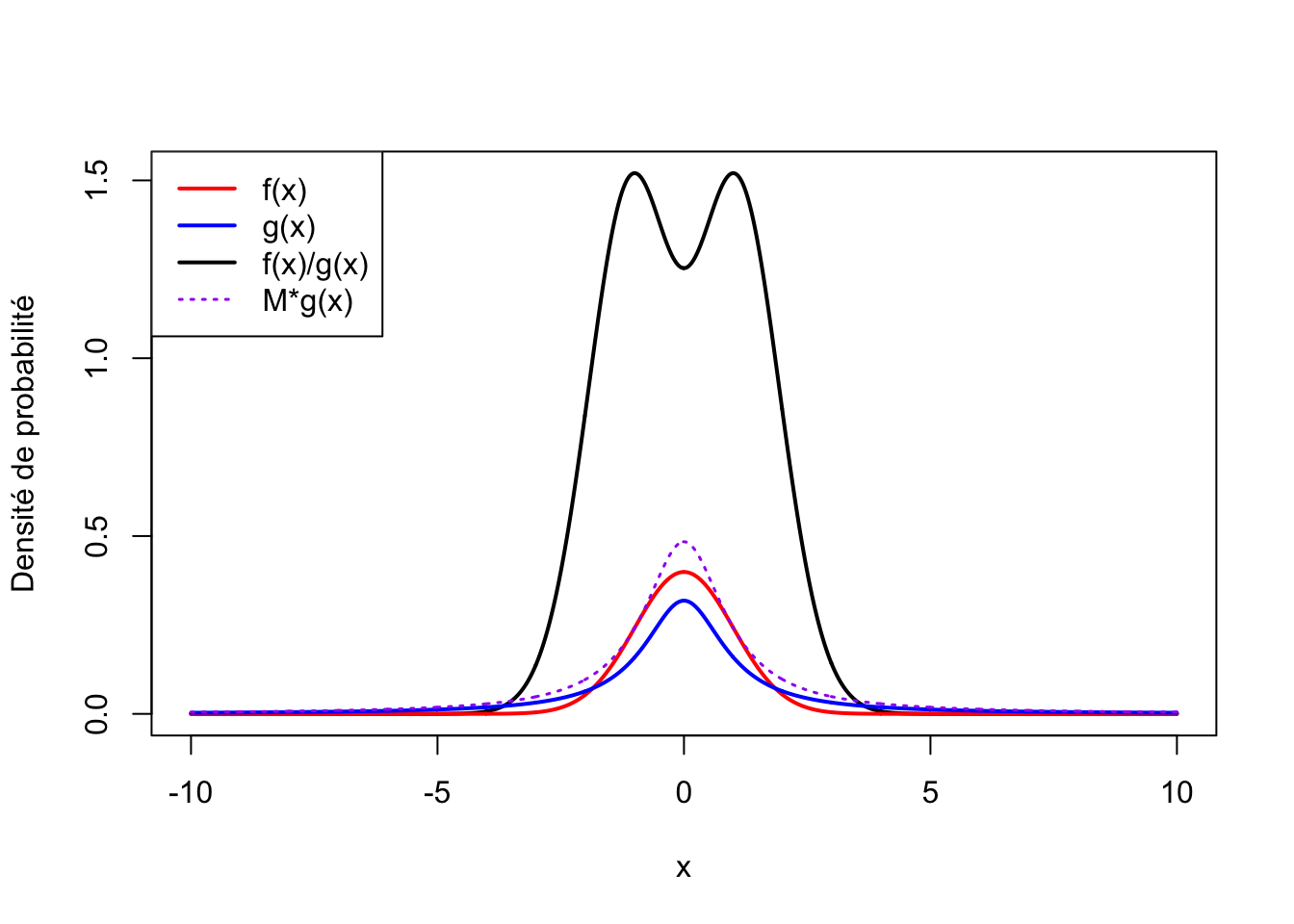
👉 Exercice 3 : Écrire un algorithme d’acceptation-rejet pour simuler la réalisation d’un pseudo-échantillon de taille \(n\) d’une loi normale \(N(0,1)\) en utilisant une loi de Cauchy comme proposition. Trouvez la valeur de \(M\) optimale.
\(f(x) = \dfrac{\exp(-x^2/2)}{\sqrt{2\pi}}\) et \(g(x) = \dfrac{1}{\pi(1+x^2)}\)
On cherche \(M\) le plus petit possible tel que \(M \geq \dfrac{f(x)}{g(x)} \,\forall\, x\).
En dérivant \(\dfrac{f(x)}{g(x)}\), on trouve \(\max\left(\dfrac{f(x)}{g(x)}\right)\) pour \(x=-1\) ou \(x=1\) (la dérivée s’annule en -1,0, et 1). Donc \(\dfrac{f(x)}{g(x)}\leq \sqrt{\dfrac{2\pi}{e}}\)
On va donc utiliser : \(M = \sqrt{\dfrac{2\pi}{e}}\)
f <- function(x){
exp(-x^2/2)/sqrt(2*pi)
}
g <- function(x){
1/(pi*(1+x^2))
}
x <- seq(from = -10, to = 10, by = 0.01)
plot(x=x, y=f(x)/g(x), type='l', lwd = 2, ylab="Densité de probabilité")
lines(x = x, y=f(x), type = "l", lwd = 2, col="red")
lines(x = x, y=g(x), type = "l", lwd = 2, col="blue")
lines(x = x, y=g(x)*sqrt(2*pi/exp(1)), type = "l", lwd = 1.5, lty=3, col="purple")
legend("topleft", legend = c("f(x)", "g(x)", "f(x)/g(x)", "M*g(x)"), col=c("red", "blue", "black", "purple"), lwd=c(2, 2, 2, 1.5), lty=c(1, 1, 1, 3))